I’ve been thinking about the WP Engine drama and whether I should take a side. Users move between Micro.blog and WordPress regularly. We’ve long had WordPress import and export, and even native posting directly to WordPress from the mobile app, plus connecting external WordPress RSS feeds.
No other platform supports WordPress as extensively as we do in Micro.blog. We compete with WordPress for hosting and also embrace it. This is what the open web is about.
In many ways, the missions of Automattic and Micro.blog are aligned. We all make software to help people write, post photos, publish podcasts, and communicate on the open web.
It’s less clear what WP Engine stands for because it is no longer run by one of its founders, Jason Cohen, someone who had a public personality and clear voice. It’s owned by private equity and the leadership has kept silent. As far as I can tell, Heather Brunner, WP Engine’s CEO, does not blog, and neither does the top leadership at Silver Lake. In other words, they do not use their company’s own product.
(As an aside, Heather is well respected in the Austin business community and praised for her mentorship to entrepreneurs. I also enjoyed her love letter to Austin in Austin Women Magazine. I would rather have more Heathers here in Austin and fewer Elons.)
Back to the drama…
I’ve followed the news and related blog posts of WP Engine vs. Automattic ever since it began. I’ve watched Matt Mullenweg’s keynotes at WordCamp US Portland (where he called out WP Engine) and WordCamp Tokyo (last week). I’ve posted briefly a few times about how Matt’s actions have hurt the community, even if he has a defensible position in trademark law.
Now there’s this article in Inc magazine. Matt, writer David Freedman suggests, just might be a mad king, a benevolent dictator for life taking WordPress in the wrong direction:
Mullenweg’s war on WP Engine has also cast a shadow over the entire world of open-source software—software that, like WordPress, can be freely downloaded and modified. Open-source software of various types is widely used throughout the world, precisely because it is seen as being free from the risk of proprietary abuse. But the WordPress debacle has demonstrated all too sharply that this belief may have been misplaced.
Most of all, it has raised questions about Mullenweg himself.
Matt responded on his own blog in detail, including this bit about taking the long view:
It’s funny to talk about the last big controversy in WordPress world being in 2010, I think it actually speaks to our stability. Since 2010, when “some eventually even left WordPress”, the platform has grown market share from under 10% to 43%. I think in a few years we’ll look back at WP Engine as inconsequential as Thesis, and Heather Brunner as credible as Chris Pearson.
I don’t know Matt personally but I get the impression that he is exhausted. I’m sure I would be overwhelmed in his shoes. I honestly lose sleep even when only a few customers on Micro.blog are upset about something I wrote.
I hope that my customers and readers, even when they disagree with me — even new readers finding this very post — still respect that I’m dedicated to making my product better because that in turn helps users make the web better. I’m putting my WordPress thoughts down in writing on my blog because I believe in the open web.
One positive outcome of this whole drama is shedding light on the WordPress Foundation, the WordPress.org website, and the plugin directory. I do think the community would benefit from expanding the WordPress Foundation to a slightly larger board and more transparent management of WordPress.org. Matt could add two more members to the board and ask for nominations from the community.
Some people think that wouldn’t go far enough, that WordPress would be better off with someone new taking over Matt’s role across the project. I’m not convinced. WordPress and Automattic didn’t accidentally become successful. They are successful in large part because of Matt and the teams he built.
WordPress with completely new leadership from the community would risk watering down the vision, bogged down by committee. The Gutenberg editor is a good case study. Such a massive, controversial change needed a champion with power. The block-based design of Gutenberg isn’t for me, and in Micro.blog we are taking the opposite approach — focus on Markdown and HTML, formats that scale well from microblog posts to full-length posts — but if you are competing with Squarespace and thinking of the needs of non-bloggers, going all-in on Gutenberg is justifiable.
The safer choice that had been advocated for by some in the community — to support both Gutenberg and the classic editor indefinitely, as peers — would have slowed down development, eventually leading to a UI mess without a unifying purpose. I’m singling out Gutenberg but take any other potential feature and run it through the feedback of an oversight committee, the outcome is the same. Bloat.
Directionless products fail. They lose their soul.
On the internet we are too quick to vilify our heroes. Someone who has built up a great reputation over many years makes a mistake and boom, they’re out. I can’t get behind that. When the mob gathers, that’s when we should stop to take a breath, to be certain we’re right.
When the narrative turns against you, even harmless decisions are questioned. Matt announced this week that WordPress.org would pause registrations and plugin reviews for the holidays. At any other time without the WP Engine backdrop this decision would not be controversial. The narrative warps reality, amplifying only one side.
Because Micro.blog is a competitor to Automattic for blog hosting, it would be an easy business decision for me to use the WP Engine drama to entice WordPress customers looking for a new blog host. That would come dangerously close to caring more about money than principles, though. Instead, everything starts with what we believe in, and the business priorities follow that.
If I must take a side, I will side with people who share my vision for a better web. I believe Matt shares that vision. Perhaps the best summary of my take is this post on my blog last month, which didn’t have anything to do with WordPress:
In 2018, when I added ActivityPub support to Micro.blog, I faced a choice: do I fight other “competing” platforms or do I embrace them? In hindsight that decision is obvious. I support anything that makes the web better. Twitter / X migration to Bluesky at scale makes the web better, so I’m for it.
Let’s keep our eyes on the big picture.
Is Matt a little crazy to go to war against WP Engine, in the process also appearing vindictive to his critics in the community? Yes. The safe, predictable path would be to take a step back. And Matt can be reflective and self-critical, like when he realized he went too far in his blog post attacking David Heinemeier Hansson and so retracted it. But good leaders often go against the flow of what everyone else thinks. This is the same quality that makes them capable of building something new.
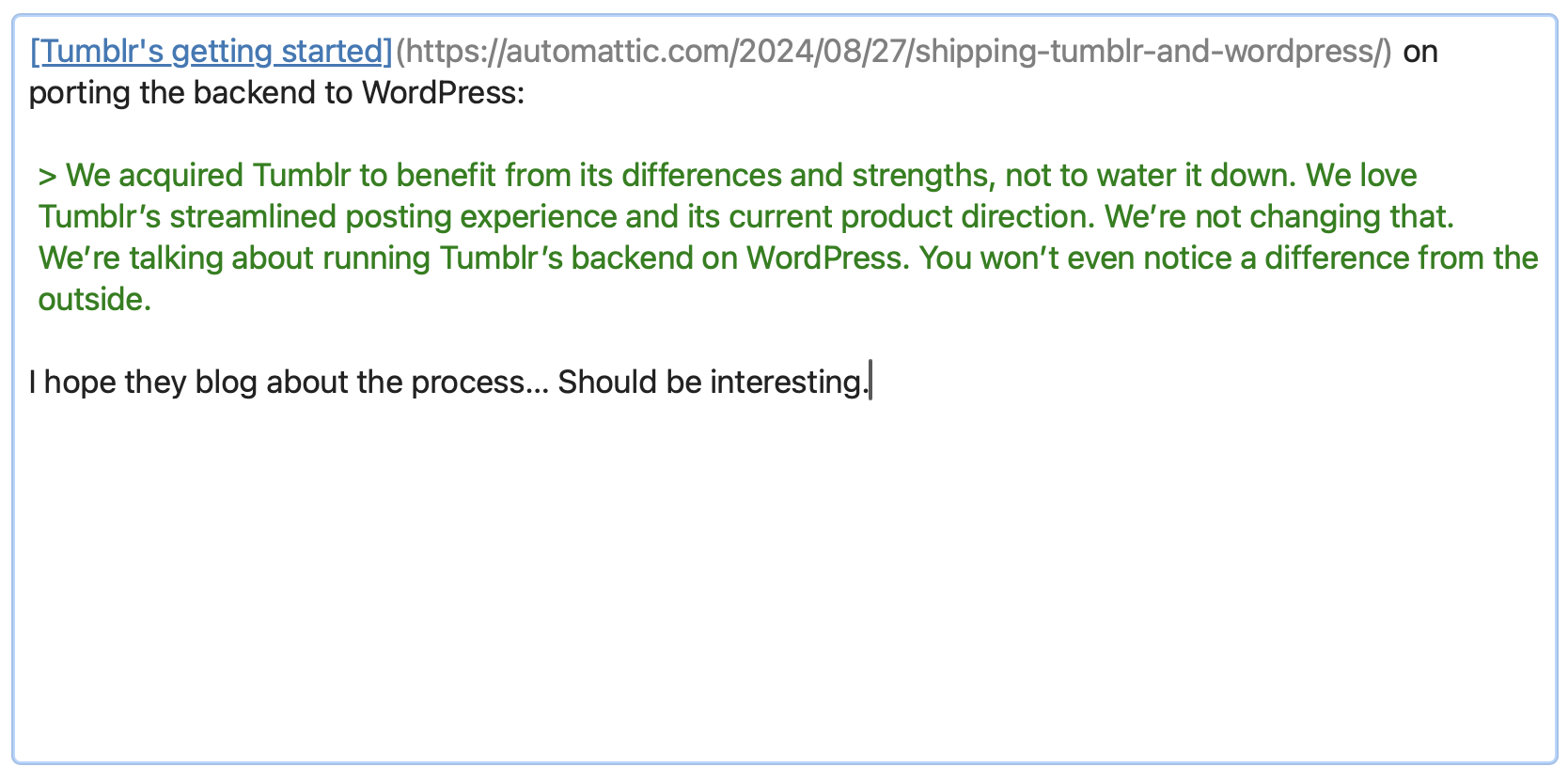
No one else would have risked their reputation to continue to attack WP Engine. But also, no one else would have acquired Tumblr and run it at a loss to preserve the culture and post archive, just because they saw the potential for what it could become again. How quickly we forget the triumphs of the mad king.
Years ago on Core Intuition, I said to Daniel that of all the new web companies, there are only two that will last 100 years, still hosting our stuff at URLs that don’t change: GitHub and Automattic. I stand by that. There are now cracks in Automattic’s inevitably, but the foundation is strong and it will hold.